PDFから画像を抽出 アクションは、対象のPDFファイルから画像データを取得するアクションです。
PDFファイル内の画像をpng形式で保存することができます。
PDF内のテキストを文字列(テキスト形式)として取得したい場合は、「PDFからテキストを抽出」アクション、表形式のデータを取得したい場合は「PDFからテーブルを抽出する」アクションを使用しましょう。
PDFに画像がデータとして保存されている必要があるため、紙の書類等をスキャンしてPDFファイル化した場合は本アクションを使用できない点に注意しましょう。
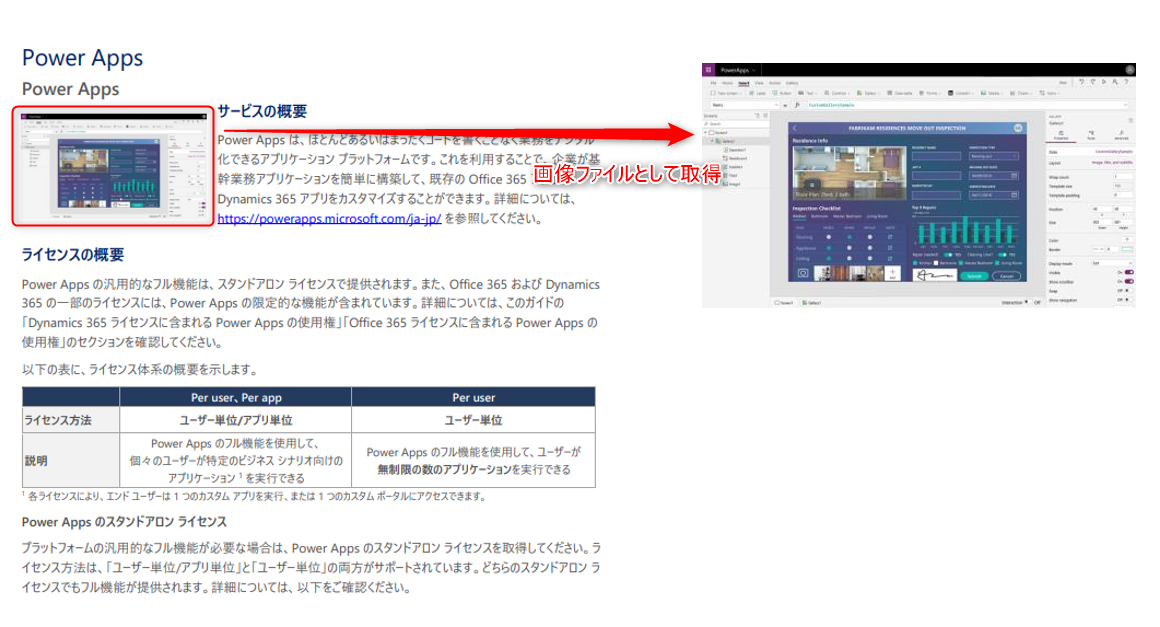
アクションの使い方
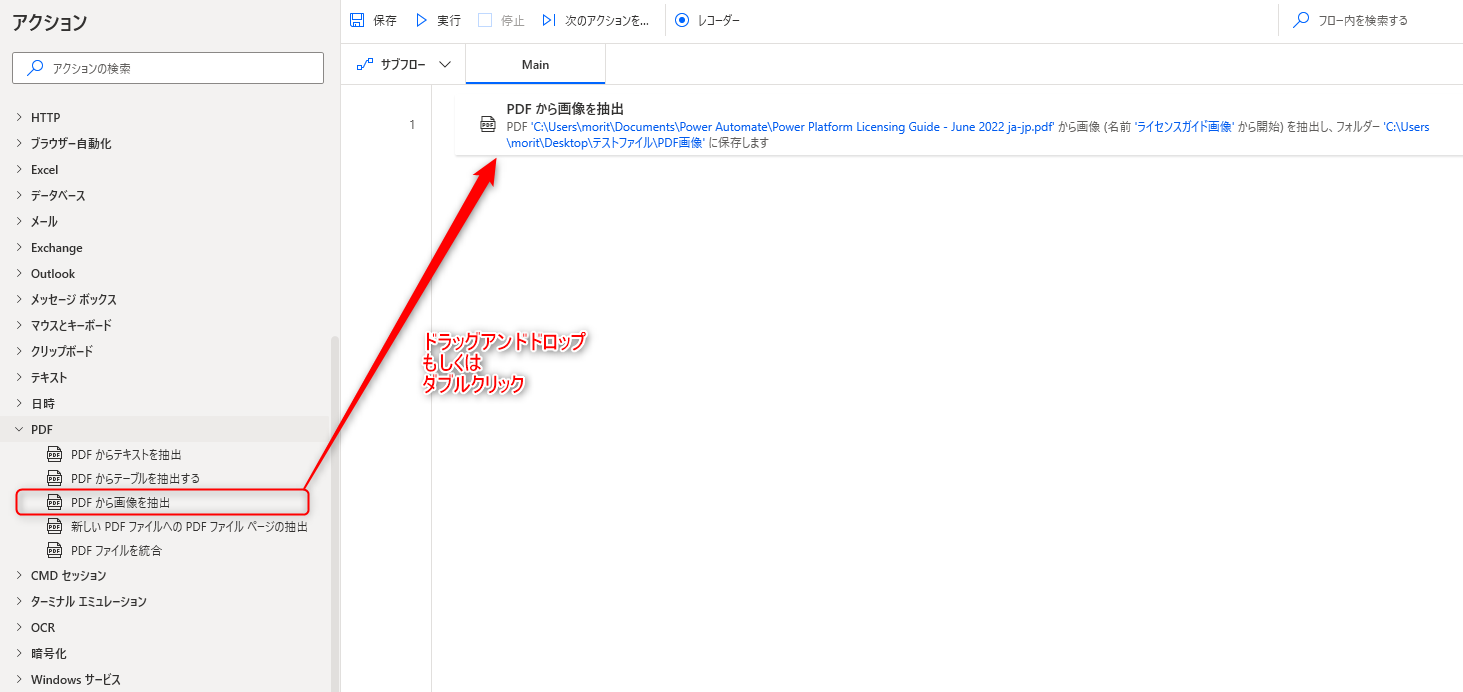
追加方法
アクションの「PDF」グループより、「PDF から画像を抽出」アクションを選択し、ドラッグアンドドロップ もしくは ダブルクリックすることでフローに追加できます。
パラメータ
アクションを追加した際に、パラメータを設定します。
各パラメータと詳細について以下で説明します。
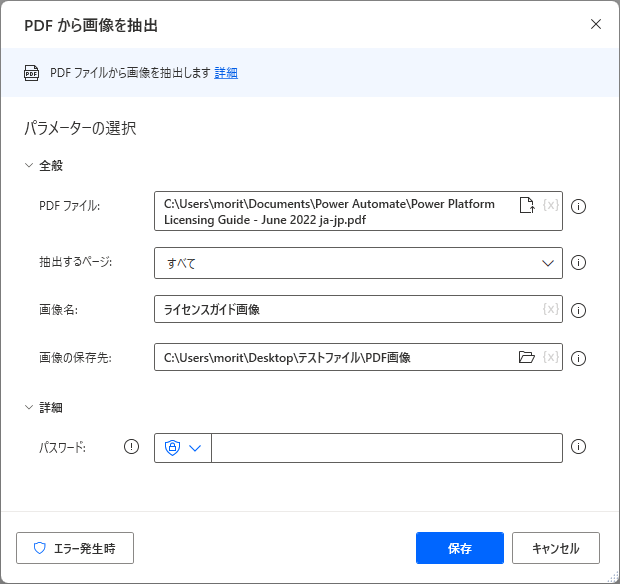
PDF ファイル
テキストを取得したいPDFファイルのパスを設定します。
ファイルパスは直接入力、ファイルの選択、変数から選択できます。

抽出するページ
テキストを取得する対象のページを設定します。
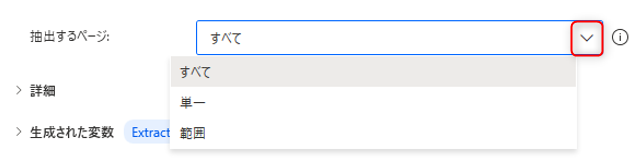
- すべて
対象とするPDFファイルの全ページからテキストデータを抽出します。
- 単一
指定した1ページからテキストデータを抽出します。
抽出するページを「単一」に設定すると、"単一ページ番号"の項目が表示され、直接入力もしくは変数にて抽出する対象のページを設定できます。
![]()
- 範囲
指定した複数のページからテキストデータを抽出します。
抽出するページを「範囲」に設定すると、"開始ページ番号"と"終了ページ番号"の項目が表示され、直接入力もしくは変数にて抽出する対象のページを設定できます。

画像名
取得した画像を保存する際の名称を設定します。
![]()
対象とするページ範囲内に複数の画像が存在する場合は、以下の様に画像名にサフィックス(連番)が付与されて保存されます。

画像の保存先
取得した画像を保存するフォルダーのパスを設定します。
フォルダーパスは直接入力、ファイルの選択、変数から選択できます。

詳細
パスワード
PDFファイルにパスワードが設定されている場合は、本項目で対象とするPDFファイルのパスワードを設定することで処理を行うことができます。

パスワードはダイレクトパスワードと変数から選択できます。
ダイレクトパスワードとした場合は上記の様に黒塗りとなり、暗号化されます。
暗号化された値は、フローを共有した際に使用できない点に注意しましょう。
生成された変数
アクション実行時に変数は生成されません。
発生する可能性があるエラー
ファイルが存在しません
PDFファイルに指定したファイルが存在しない場合に発生するエラーです。
設定したファイルパスやファイル名に誤りがないか、指定したファイルが存在するかを確認してみましょう。
フォルダーが存在しません
保存先に指定したフォルダーが存在しない場合に発生するエラーです。
設定したフォルダーパスに誤りがないかを確認してみましょう。
無効なパスワード
PDFファイルのパスワードが解除できない場合に発生するエラーです。
パスワードの項目に設定している値が正しいか確認してみましょう。
引数は整数値である必要があります
ページ番号に設定した値が整数値でない場合に発生するエラーです。
ページ番号に平仮名やアルファベットといった文字が入力されていないか確認してみましょう。
Power Automate for desktop アクション一覧
Power Automate for desktopのアクション一覧と使い方を以下でまとめています。
是非参考としてみて下さい。
-

Power Automate for desktop アクション一覧・使用方法
Power Automate for desktopのアクションをグループごとにまとめています。 目次から目的のアクショングループを選択して参照ください。 各アクションの使用方法については、アクション ...
続きを見る